
HashMap Implementations Across Various Programming Languages
HashMap Implementations Across Various Programming Languages
HashMap, a versatile data structure, finds its implementation across different programming languages. Let’s delve into its implementations and internal workings.
Java/Groovy (JVM)
In Java and Groovy, HashMap is implemented using `java.util.HashMap` from the Java Collections Framework.
C++ (STL)
C++ utilizes `std::unordered_map` from the Standard Template Library (STL) to implement HashMap functionality.
JavaScript
In JavaScript, objects serve as HashMaps, offering a convenient way to store and retrieve data using keys.
Python
Python provides built-in HashMap data structures through dictionaries, offering efficient key-value pair storage and retrieval.
.Net
For .Net languages, the `Dictionary<TKey, TValue>` class from `System.Collections.Generic` serves as the HashMap implementation.
Internal Implementation of HashMap
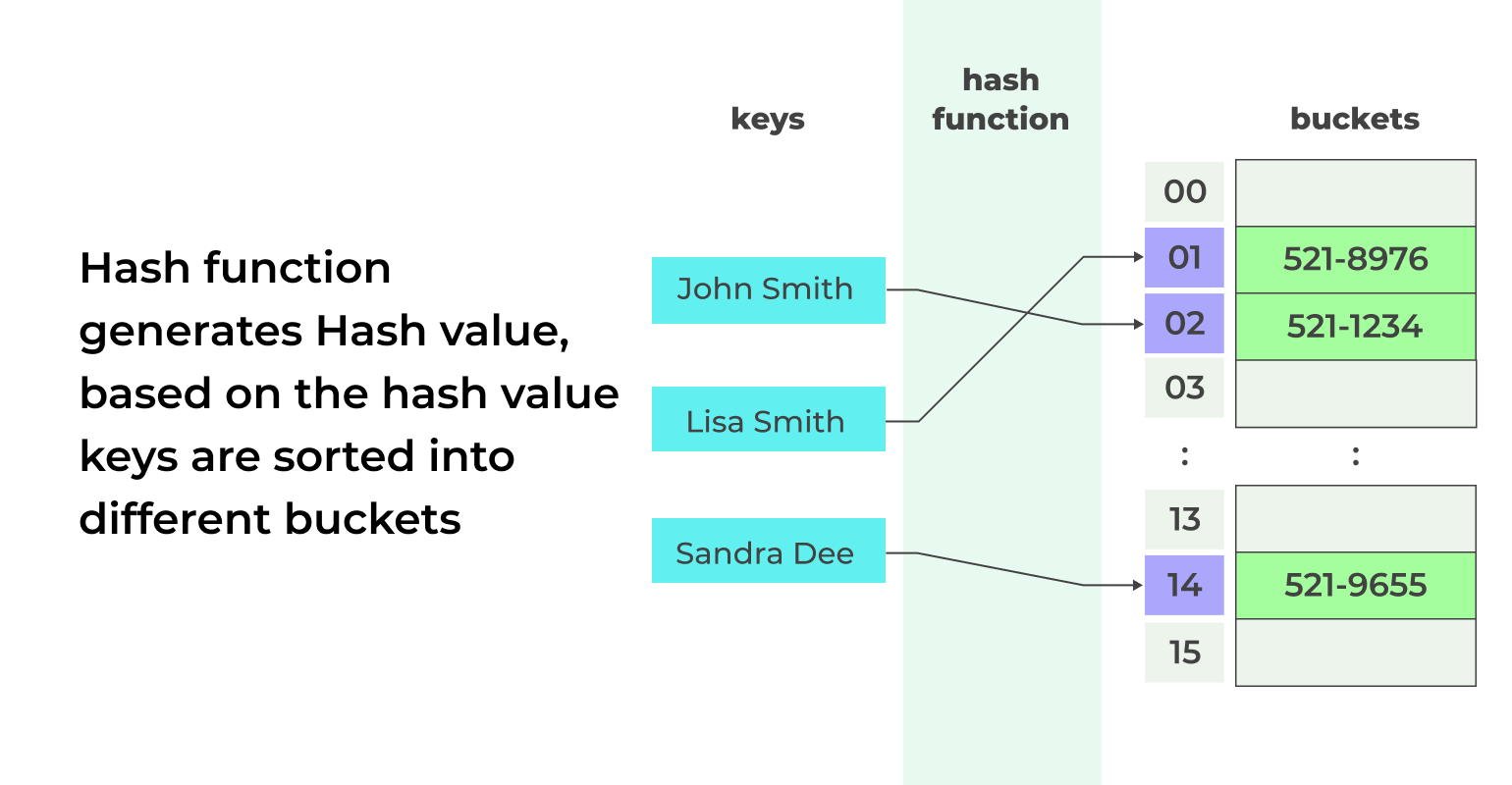
HashMap operates on the principle of Hashing, employing three key components: Hash Function, Hash Value, and Buckets.
- Hash Function: `hashCode()` function generates an integer value, determining the Hash Value. This method is present in the Object class and is used to calculate the hash of keys.
- Hash Value: The integer value returned by the hash function.
- Bucket: Buckets store key-value pairs, with each bucket capable of holding multiple pairs. In HashMap, buckets typically use a simple linked list to manage objects.
Understanding the Hash Function in the String Class
- Here the code calculates the hash using the Multiplication-Addition hash Algorithm.
- This code computes the hash code of a byte array by iterating through its elements.
- For each byte, it multiplies the current hash code by 31 and adds the byte value (considering only the last 8 bits) using bitwise AND with 255.
public static int hashCode(byte[] value)
{
int h = 0;
byte[] var2 = value;
int var3 = value.length;
for(int var4 = 0; var4 < var3; ++var4)
{
byte v = var2[var4];
h = 31 * h + (v & 255);
}
return h;
}
What if two keys share the same hashcode
Collision: If two keys end up calculating same hash it is called collision.
- To tackle such collisions within our hashmap, we implemented a solution by employing linked lists as buckets.
- So the key with the same hashcode will be appended to the linked list/bucket.
- During the insertion process, we traverse the entire linked list. If there isn’t an existing key with the same name, the value is inserted. Otherwise, the existing value associated with the key is updated.
- If the list grows longer and longer again the cost of fetching value is higher
i.e O(size of list).
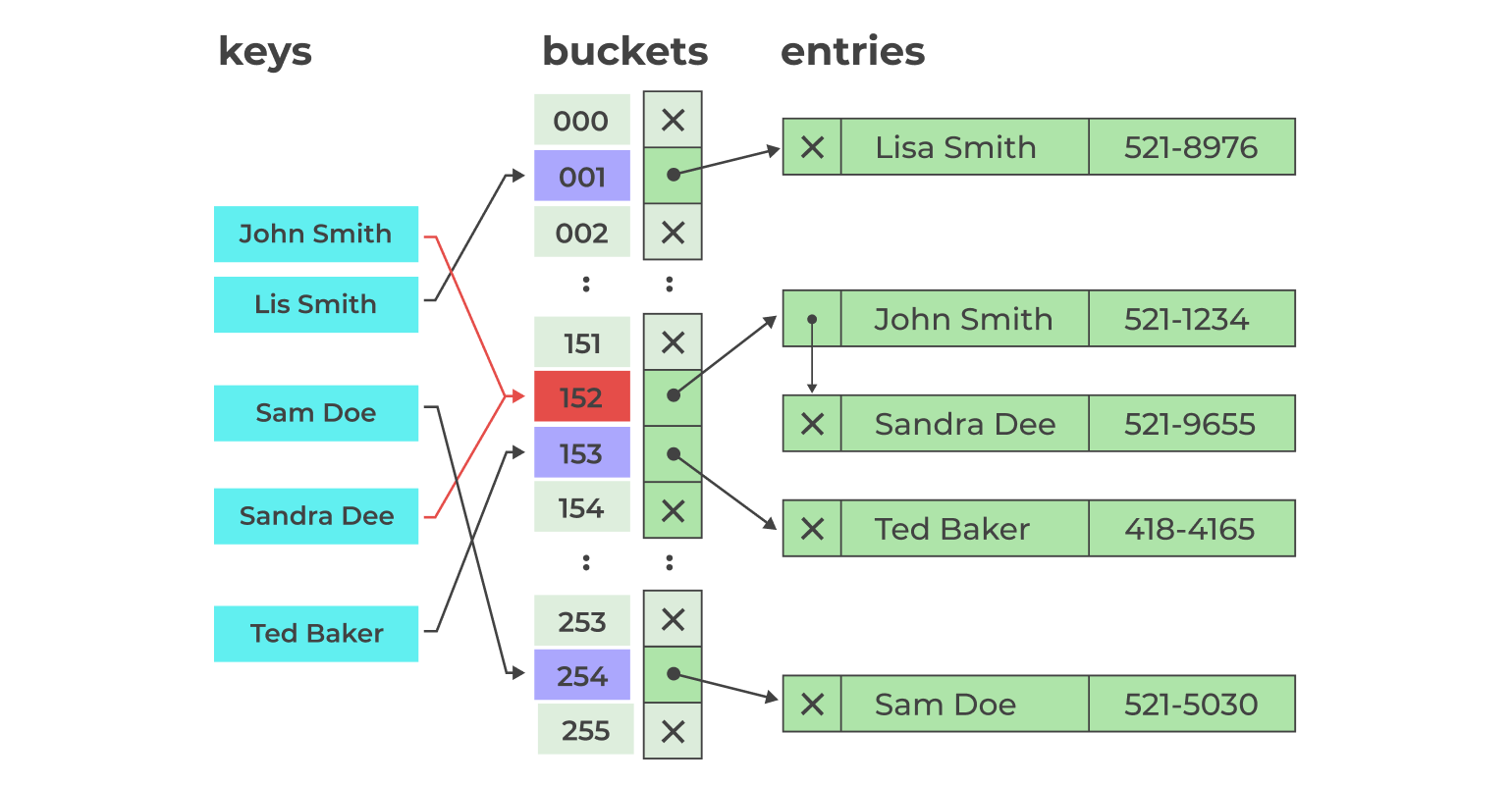
The image above illustrates two keys ending up within the same bucket (152).
What if the linked list becomes lengthier?
- Considering that the linked list grows longer, the time complexity of put(), get(), and search operations will increase to O(length of the linked list).
- To address this issue we can implement another data structure whose time complexity for the above-mentioned operation is less.
- One such alternative is Red Black Tree (self-balancing binary search tree).
- Time complexity of Put() and get()/search operation in Red Black tree is
O(log(size of tree)) (Divide and conquer).
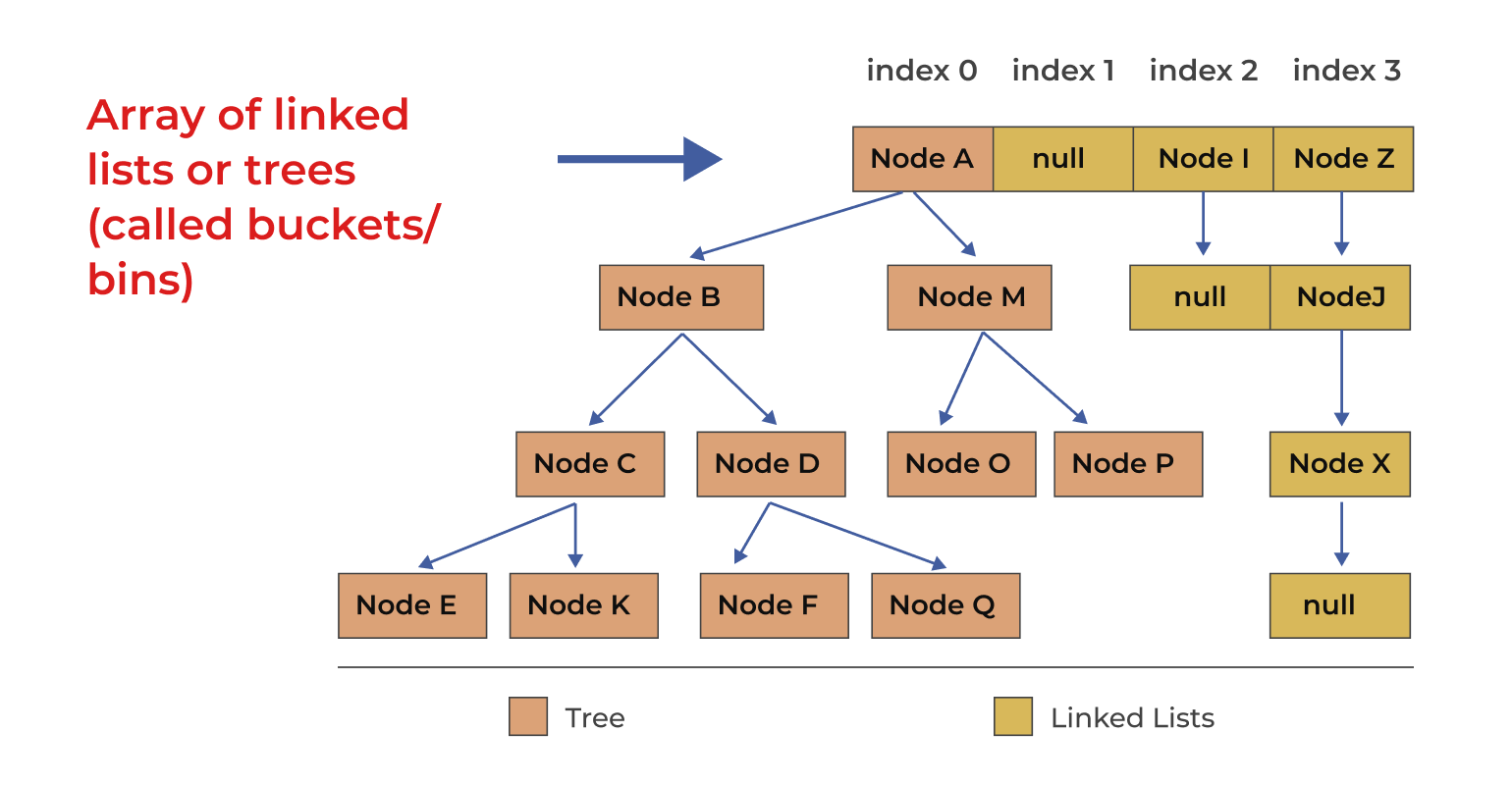
The image above depicts buckets that implement Linked Lists and others that implement Trees.
Conclusion
HashMap serves as a fundamental data structure for efficient storage and retrieval of key-value pairs. Across various programming languages, different implementations exist, each tailored to the language’s specific characteristics. Understanding the internal workings of HashMap and its collision handling mechanisms is crucial for designing robust and efficient software systems.
